Knowledge Graph and LLM Integration: Benefits & Challenges
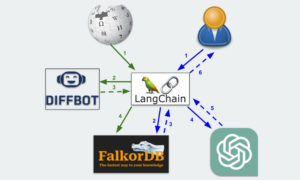
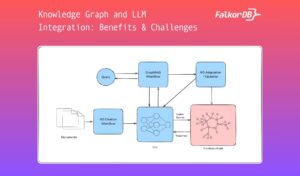
What is LLM and Knowledge Graph Integration? In today’s AI landscape, there are two key technologies that are transforming machine understanding, reasoning, and natural language processing: Large Language Models (LLMs) and Knowledge Graphs (KGs). LLMs, like OpenAI’s GPT series or Meta’s Llama series, have shown incredible potential in generating human-like text, answering complex questions, and creating content across diverse fields. Meanwhile, KGs help organize and integrate information in a structured way, allowing machines to understand and infer the relationships between real-world entities. They encode entities (such as people, places, and things) and the relationships between them, making them ideal for tasks such as question-answering and information retrieval. Emerging research has demonstrated that the synergy between LLMs and KGs can help us create AI systems that are more contextually aware and accurate. In this article, we explore different methods for integrating the two, showing how this can help you harness the strengths of both. Source: https://arxiv.org/html/2406.08223v2 Knowledge Graph and LLM Integration Approaches You can think of the interaction between LLMs and KGs in three primary ways. First, there are Knowledge-Augmented Language Models, where KGs can be used to enhance and inform the capabilities of LLMs. Second, you have LLMs-for-KGs, where LLMs are used to strengthen and improve the functionality of KGs. Finally, there are Hybrid Models, where LLMs and KGs work together to achieve more advanced and complex results. Let’s look at all three. 1. Knowledge-Augmented Language Models (KG-Enhanced LLMs) A direct method to integrate KGs with LLMs is through Knowledge-Augmented Language Models (KALMs). In this approach, you augment your LLM with structured knowledge from a KG, thus enabling the model to ground its predictions in reliable data. For example, KALMs can significantly improve tasks like Named Entity Recognition (NER) by using the structured information from a KG to accurately identify and classify entities in text. This method allows you to combine the generative power of LLMs with the precision of KGs, resulting in a model that is both generative and accurate. 2. LLMs for KGs Another approach is to use Large Language Models (LLMs) to simplify the creation of Knowledge Graphs (KGs). LLMs can assist in creating the knowledge graph ontology. You can also use LLMs to automate the extraction of entities and relationships. Additionally, LLMs help with the completion of KGs by predicting missing components based on existing patterns, as seen with models like KG-BERT. They also ensure the accuracy and consistency of your KG by validating and fact-checking information against the corpora. 3. Hybrid Models (LLM-KG Cooperation) Hybrid models represent a more complex integration, where KGs and LLMs collaborate throughout the process of understanding and generating responses. In these models, KGs are integrated into the LLM’s reasoning process. One such approach is where the output generated by an LLM is post-processed using a Knowledge Graph. This ensures that the responses provided by the model align with the structured data in the graph. In this scenario, the KG serves as a validation layer, correcting any inconsistencies or inaccuracies that may arise from the LLM’s generation process. Alternatively, you can build the AI workflow such that the LLM prompt is created by querying the KG for relevant information. This information is then used to generate a response, which is finally cross-checked against the KG for accuracy. Benefits of Knowledge Graph and LLM Integration There are numerous benefits to integrating LLMs with Knowledge Graphs. Here are a few. 1. Enhanced Data Management Integrating KGs with LLMs allows you to manage data more effectively. KGs provide a structured format for organizing information, which LLMs can then access and use to generate informed responses. KGs also allow you to visualize your data, which you can use to identify any inconsistencies. Very few data management systems provide the kind of flexibility and simplicity that KGs offer. 2. Contextual Understanding By combining the structured knowledge of KGs with the language processing abilities of LLMs, you can achieve a deeper contextual understanding of AI systems. This integration allows your models to use the relationships between different pieces of information and helps you build explainable AI systems. 3. Collaborative Knowledge Building The KG-LLM integration also helps create systems where KGs and LLMs continuously improve upon each other. As the LLM processes new information, your algorithm can update the KG with new relationships or facts which, in turn, can be used to improve the LLM’s performance. This adaptive process can ensure that your AI systems continually improve and stay up-to-date. 4. Dynamic Learning By leveraging the structured knowledge that KGs provide, you can build LLM-powered AI systems in fields such as healthcare or finance, where data is dynamic and constantly evolving. Keeping your KG continuously updated with the latest information ensures that LLMs have access to accurate and relevant context. This enhances their ability to generate precise and contextually appropriate responses. 5. Improved Decision-Making One of the most significant benefits of integrating KGs with LLMs is the enhancement of decision-making processes. By grounding its decisions in structured, reliable knowledge, your AI system can make more informed and accurate choices, reducing the likelihood of errors and hallucinations and improving overall outcomes. An example of this is a GraphRAG system, which is increasingly being used to augment LLM responses with factual, grounded data that wasn’t a part of its training dataset. Challenges in LLM and Knowledge Graph Integration 1. Alignment and Consistency One of the main challenges you may face in integrating KGs with LLMs is ensuring alignment and consistency between the two. Since KGs are structured, while LLMs are more flexible and generative, aligning the outputs of an LLM with the structure and rules of a KG can be challenging. To ensure that both systems work together, you will need to create a mitigator that’s responsible for prompting the LLM, as well as issuing KG queries when the LLM needs additional context. 2. Real-Time Querying Another challenge is real-time querying. While KGs can provide highly accurate and structured information, querying them in real-time can be computationally expensive and